Backups automatizadas con restic
Para las backups de mis equipos personales utilizo un conjunto de herramientas que me permiten automatizar y monitorizar el flujo de backups, para tener la garantía de que se realizan de forma continua y sin depender de que me acuerde de lanzar los scripts cada cierto tiempo.
Los scripts de backups los lanza el sistema usando timers de systemd, de la monitorización se encarga un software denominado Healthchecks que bien puedes usar la versión SaaS o montar tu propia instancia en tú local.
En próximas entradas explicaré como integrar un software de monitorización y como automatizar los procesos con timers de systemd. En este explico como uso personalmente la herramienta de restic para mis backups.
Software de backup: restic
Restic es el software que uso para gestionar la mayoría de backups. Salvo en algún caso excepcional que todavía uso Borg porque no he conseguido que restic funcione bien en sistemas con Brtfs.
Este software, escrito en Go, me ha demostrado funcionar bien incluso con conexiones inestables entre el equipo del que se está haciendo la backup y el destino donde se depositan los datos.
Admite múltiples destinos, yo personalmente utilizo los repositorios en Backblaze B2 para mis copias outsource y en una máquina que tengo fuera de casa tengo instalado un REST Server para tener copias fuera de la red local.
Las copias que se ejecutan con restic van siempre cifradas en origen, por lo no hay problema en alojar estas copias en servicios en la nube.
Esquema
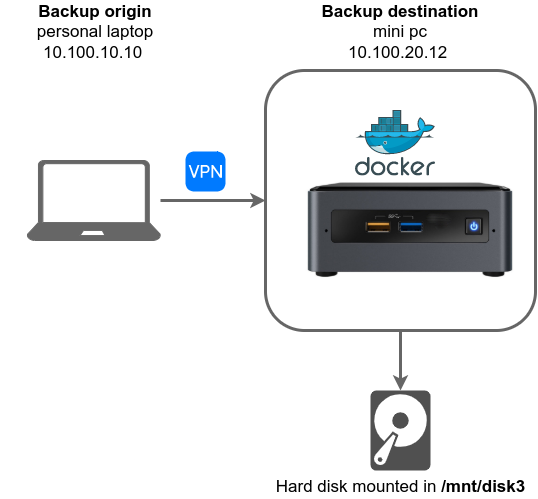
Este es el esquema en el que me baso para este ejemplo. Hay un origen (mi portátil personal) y uno de los destinos que uso, en este caso un equipo que tengo en otra localización, conectados mediante VPN y que tiene conectado un disco duro externo para almacenar las backups.
Instancia de REST Server
rest server es una pequeña utilidad desarrollada por restic para servir como servidor HTTP de alto rendimiento para el almacenamiento de ficheros. Antes tenía en la máquina destino montado un servicio de minio junto con el conector S3 de restic, pero la solución basada en rest server es más liviana y fácil de configurar.
En una máquina remota (fuera de mi red local) tengo un mini pc con un disco duro externo donde de alojan las copias (máquina destino). Este mini pc está corriendo un Ubuntu con docker, sobre el cual tengo configurado un servicio de restic rest server:
Ejemplo de fichero docker-compose.yaml en nuestra máquina remota:
version: "2.4"
services:
restic-backups:
image: restic/rest-server:latest
container_name: "restic-backup"
volumes:
- /mnt/disk3/restic_server:/data
ports:
- 9004:8000
restart: "on-failure"Este servicio expondrá, mediante una interfaz REST, el contenido de la carpeta que tenemos montada en un disco externo en la ruta /mnt/disk3/restic_server, que será el destino de las backups.
Ahora hay que añadir la autenticación. El servicio puede correr sin tener ningún tipo de autenticación pero no es recomendable. Para eso inicializamos en la raíz que vamos a usar como repositorio de datos (en mi ejemplo, /mnt/disk3/restic_server) un archivo de credenciales.
$ sudo htpasswd -B -c .htpasswd myuser
New password:
Re-type new password:
Adding password for user myuser
Así mismo es recomendable activar el cifrado SSL, ya que el mecanismo basic auth corriendo sobre una transmisión sin cifrar es realmente peligroso.
Inicialización del repositorio
En la máquina local (la máquina origen de la backup) inicializamos el repositorio. Las credenciales myuser:mypassword son las que hemos creado en el punto anterior.
$ restic -r rest:http://myuser:mypassword@10.100.20.12:9004/ init
enter password for new repository:
enter password again:
created restic repository 9a0c397f1b at rest:http://myuser:***@localhost:9004/
Please note that knowledge of your password is required to access
the repository. Losing your password means that your data is
irrecoverably lost.
El password que nos solicita en este paso es muy importante. Es la calve de cifrado del repositorio y lo necesitaremos en las operaciones de backup, restauración, etc por lo que debemos de guardarlo en un sitio seguro, por ejemplo en nuestro vault.
Creación de una nueva copia de seguridad
En la documentación oficial hay ejemplos de funcionamiento de la creación de “snapshots”. El funcionamiento es sencillo, este es un ejemplo de creación de snapshot de todo la carpeta home
| |
restic nos solicitará la clave de cifrado en el momento de arrancar el script. Para automatizar este proceso es necesario por tanto establecer la clave ya sea por variable de entorno en el mismo script RESTIC_PASSWORD=xxx o en un fichero independiente con los permisos necesarios RESTIC_PASSWORD_FILE=/miPasswordFile. En el ejemplo uso la segunda opción.
Es importante que el fichero sea solo accesible por el usuario que vaya a ejecutar el script de backup, para evitar que otros usuarios puedan acceder a la clave de cifrado.
Documentación: link
Mantenimiento del repositorio
Además de crear las backups cada día, hay que ejecutar operaciones de mantenimiento para mantener en perfecto estado el repositorio de datos.
Operación prune
Cada vez que lanzamos una nueva backup con restic backup se crea un nuevo snapshot. Estos snapshots ocupan un espacio, y si no se eliminan de forma periódica acabarían ocupando todo el espacio disponible en el destino.
Lo mejor para un proceso automatizado es establecer una política de snapshots para mantener un conjunto de snapshots que nos interesen: las backups de los últimos n días, una backup por semana de las últimas n semanas, etc. En la documentación de restic se detallan todas las opciones.
| |
En este ejemplo, mantenemos un snapshot de los últimos 7 días, un snapshot semanal de las últimas 6 semanas y un snapshot mensual de los últimos 2 años.
El parámetro --prune (o la instrucción restic prune) sirve para, una vez eliminadas los snapshots, borra los datos asociados para liberar espacio. forget elimina las referencias a esos snapshots, y prune elimina los datos asociados para liberar el espacio.
Esta es una operación costosa que puede llevar mucho tiempo (sobretodo con prune), y además que no debe de ejecutarse al mismo tiempo que una backup. Yo la ejecuto cada semana / 15 días.
Documentación: link
Operación check repositorio
Es conveniente ejecutar de forma regular las operaciones de comprobación del estado de nuestras backups en el destino. Es importante para que no ocurra que el día que tengamos que recurrir a ellas estén dañadas y no podamos recuperar nada 😰.
Las comprobaciones de restic se basan en dos puntos:
- consistencia e integridad estructural del propio repositorio
- integridad de los propios datos
Comprobar el primer punto es relativamente rápido, es la comprobación por defecto del script restic check.
La segunda comprobación es más completa pero lenta. Se ejecuta indicando el parámetro --read-data. Require que restic descargue en el equipo origen los datos del repositorio remoto para realizar la comprobación.
Esto es costoso a nivel de tiempo, ancho de banda e incluso a nivel económico 💸. Algunos destinos como Backblaze B2 por ejemplo cobran por MB descargado.
Una opción más factible es realizar chequeos “parciales” donde comprobemos la consistencia del repositorio y una parte de los datos.
| |
Hay opciones que permiten filtrar directorios o ficheros para excluir de la backup. En el script de ejemplo utilizo el parámetro --exclude-if-present para ignorar todos los directorios que tengan un fichero .nobackup, así solo tengo que hacer un touch .nobackup en los repositorios que quiero que sean ignorados.
Documentación: link